해당 글은 엘라스틱 스택 개발부터 운영까지라는 책 중 5장을 정리하여 쓴 글입니다.
엘라스틱서치도 데이터를 날짜별로 묶거나 특정 카테고리별로 묶어 그룹별 통계를 내는 집계 개념(aggregation)이 있다.
집계? 데이터를 그룹핑하고 통계값을 얻는 기능이다. 집계 기능은 강력한 검색 성능과 맞물려 엘라스틱서치를 고성능 집계 엔진으로 사용할 수 있도록 한다. 대표적인 예로 키바나가 있다.
집계의 종류는 메트릭 집계, 버킷 집계, 파이프라인 집계가 있다.
집계의 Request와 Response
Request

집계의 Requset는 aggs로 시작을 한다.
aggs는 집계 요청을 하겠다는 의미, my_aggs는 사용자가 지정하는 집계 이름이다. agg_type은 집계 타입을 의미한다. 집계 타입에 대해서는 메트릭 집계와 버킷 집계의 타입이 있다. 메트릭 집계는 통계나 계산에 사용되며, 버킷 집계는 도큐먼트를 그룹핑하는 데 사용된다.
Response

집계의 응답은 hits와 aggregations가 있다. hits는 집계에 사용된 리스트를 보여준다.
단, 엘라스틱서치는 기본적으로 보여주는 사이즈가 설정하지 않는 이상 기본 10으로 고정되기 때문에, 10개가 나온다고 이상하다고 하지는 말자.
aggregations는 응답 메시지가 집계 요청에 대한 결과임을 알려준다. my_agg는 request에서 지정한 집계 이름이다. 그 안의 value는 실제 집계 결과가 나온다. 요청의 집계의 계층, 타입, 구성에 따라 결과의 형태는 변할 수가 있다고 한다.
메트릭 집계
메트릭 집계? 필드의 최소/최대/합계/평균/중간값 같은 통계 결과를 보여준다.
| 메트릭 집계 | 설명 |
| avg | 필드의 평균값을 계산한다 |
| min | 필드의 최솟값을 계산한다. |
| max | 필드의 최댓값을 계산한다. |
| sum | 필드의 총합을 계산한다. |
| percetiles | 필드의 백분윗값을 계산한다. |
| stats | 필드의 min, max, sum, avg, count(도큐먼트 개수)를 한 번에 볼 수 있다. |
| cardinality | 필드의 유니크한 값 개수를 보여준다. |
| geo-centroid | 필드 내부의 위치 정보의 중심점을 계산한다. |
평균값/백분위 집계 구하기
평균값

평균 집계는 avg를 사용한다.
avg? 필드의 평균값을 계산한다
평균 집계를 사용하려면 Request에서 aggrs안에 집계 이름을 두고 (현재 집계 이름 stats_aggs이다.), 집계 이름 안에서 avg를 사용하면 된다. avg를 사용했을 때의 주의점이 있는데, 바로 필드 타입이 정수나 실수 타입이어야 한다.
size를 0으로 설정한 이유는 집계에 사용한 도큐먼트를 결과에 포함하지 않음으로써 비용을 절약하기 위해서이다.
이러한 집계에 대한 응답은 aggregations의 value에 34.88652318578368이 나온 것을 확인할 수가 있다.
백분위 집계

백분위 집계를 하기 위해서는 percentiles를 사용해야 한다.
percentiles ? 필드의 백분윗값을 계산한다.
percentiles 안에는 그에 맞는 field가 있고, 백분위에 대한 범위 지정도 할 수가 있다. 현재 예시는 25,80으로 하였다. 즉, 25%, 80%에 속하는 데이터를 요청한다는 것이다.
이러한 백분위 집계에 대한 응답은 25퍼 : 16.984375, 80퍼 : 50으로 나왔다.
필드의 유니크한 값 개수 확인하기

필드의 유니크한 값들의 개수를 확인하기 위해서는 cadinality 집계를 사용하면 된다.
cardinality 집계 ? 필드의 중복된 값들을 제외하고 유니크한 데이터의 개수만 보여준다. 일반적으로 범주형 데이터에서 유니크한 데이터를 확인하는 용도로 많이 사용된다.
SQL의 distinct count라고 이해하면 편하다.
요청에 대해서 cardinalty를 사용하면 되고, 대상 field를 입력하여 요청을 하면 된다.
precision_threshold 파라미너는 정확도 수치라고 이해하자. 값이 크면 정확도가 올라가는 대신 시스템 리소스를 많이 소모하고, 값이 작으면 정확도는 떨어지는 대신 시스템 리소스를 덜 소모한다.
추가로 cardinality는 HyperLogLog++ 알고리즘을 사용하여 메모리로 집합의 원소 개수를 추정한다. (집합의 원소 개수를 추정하기 때문에 value에 나오는 값보다는 작게 설정을 하지 않는 것을 추천한다. 값이 다르게 나올 수가 있다.) 즉, 원소 개수와 정확도 수치인 precision_threshold 파라미터를 이용해 정확도와 리소스를 등가 교환한다. 기본값은 3000이며 최대 40000이다.
응답에 대해서 value가 7이 나온 것을 볼 수가 있다. 7은 바로 day_of_week에 맞게 요일의 개수 7을 의미한다. 즉 월,화,수,목,금,토,일이 day_of_week 필드에 다 들어가 있다고 생각하면 된다.
검색 결과 내에서의 집계
검색 쿼리와 함께 집계를 사용하는 방법도 있다.
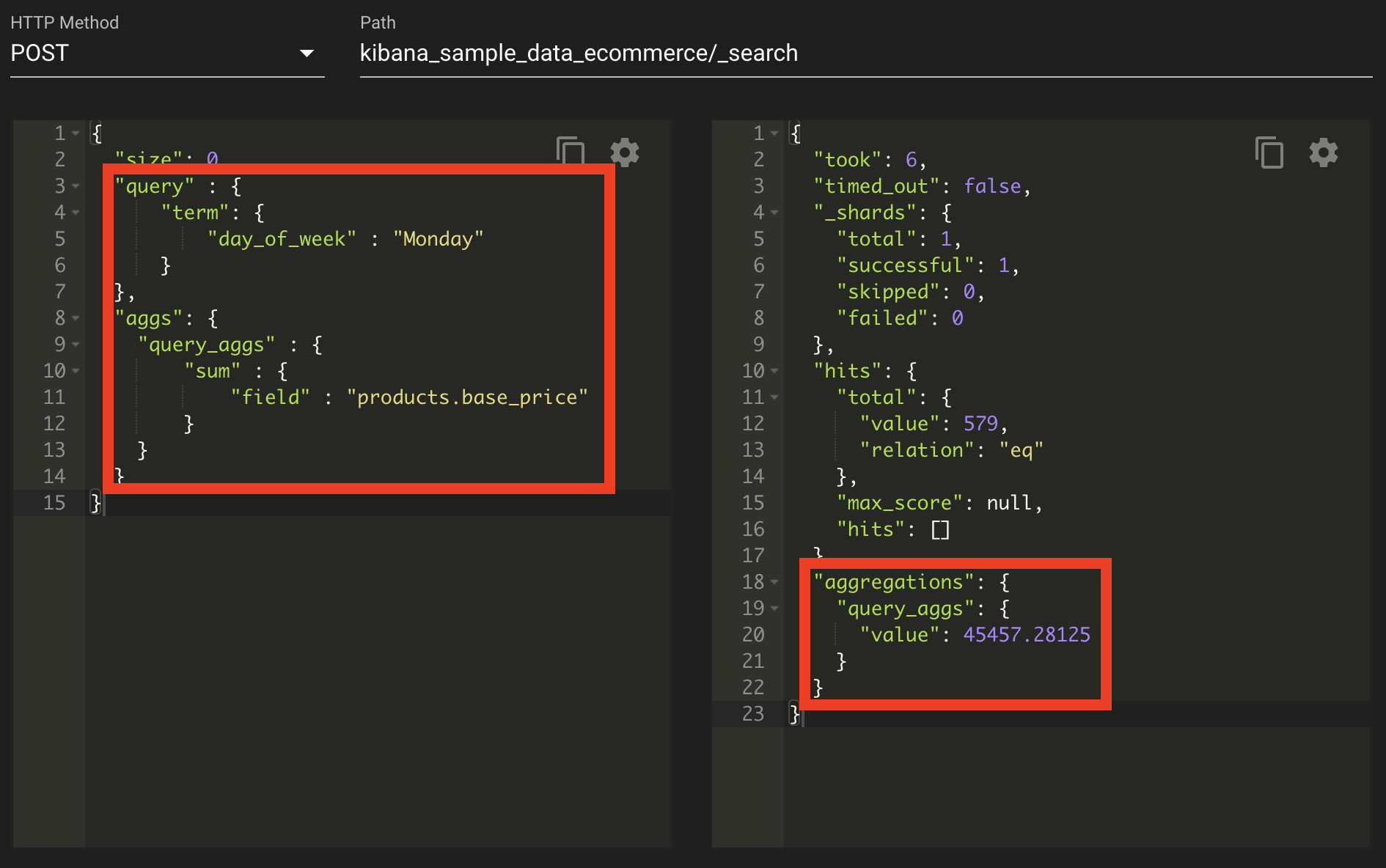
위의 쿼리는 월요일에 등록된 상품의 가격을 합계를 내는 것이다. 좀 더 풀어쓰면 query를 통하여 day_of_week에서 monday를 찾고, 이를 aggs를 사용하여 sum을 하면 검색 쿼리와 함께 집계가 되어 결과 값인 45457.28125가 나오는 것을 볼 수가 있다.
버킷 집계
메트릭 집계가 특정 필드를 기준으로 통계값을 계산하려는 목적이라면, 버킷 집계는 특정 기준에 맞춰서 도큐먼트를 그룹핑하는 역할을 한다. 버킷은 도큐먼트가 분할되는 단위로 나뉜 각 그룹을 의미한다.
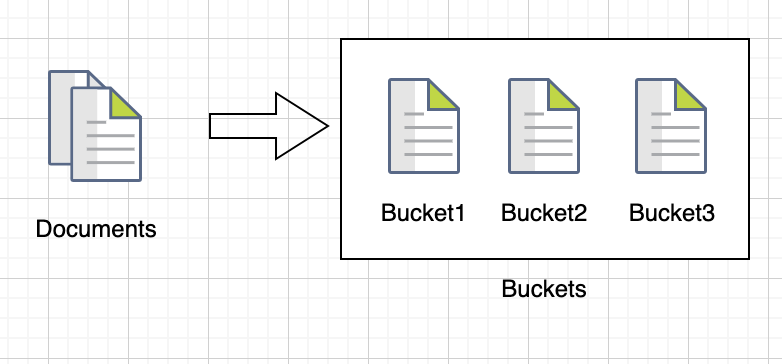
버킷 집계 종류
| 버킷 집계 | 설명 |
| histogram | 숫자 타입 필드를 일정 간격으로 분류한다. |
| date_histogram | 날짜/시간 타입 필드를 일정 날짜/시간 간격으로 분류한다. |
| range | 숫자 타입 필드를 사용자가 지정하는 범위 간격으로 분류한다. |
| date_rage | 날짜/시간 타입 필드를 사용자가 지정하는 날짜/시간 간격으로 분류한다. |
| terms | 필드에 많이 나타나는 용어(값)들을 기준으로 분류한다. |
| singificant_terms | terms 버킷과 유사하나, 모든 값을 대상으로 하지 않고 인덱스 내 전체 문서 대비 현재 검색 조건에서 통계적으로 유의미한 값들을 기준으로 분류한다. |
| filters | 각 그룹에 포함시킬 문서의 조건을 직접 지정한다. 이때 조건은 일반적으로 검색에 사용되는 쿼리와 동일하다. |
히스토그램 집계 / 범위 집계 / 용어 집계 구하기
히스토그램 집계
histogram ? 숫자 타입 필드를 일정 간격 기준으로 구분해주는 집계이다.
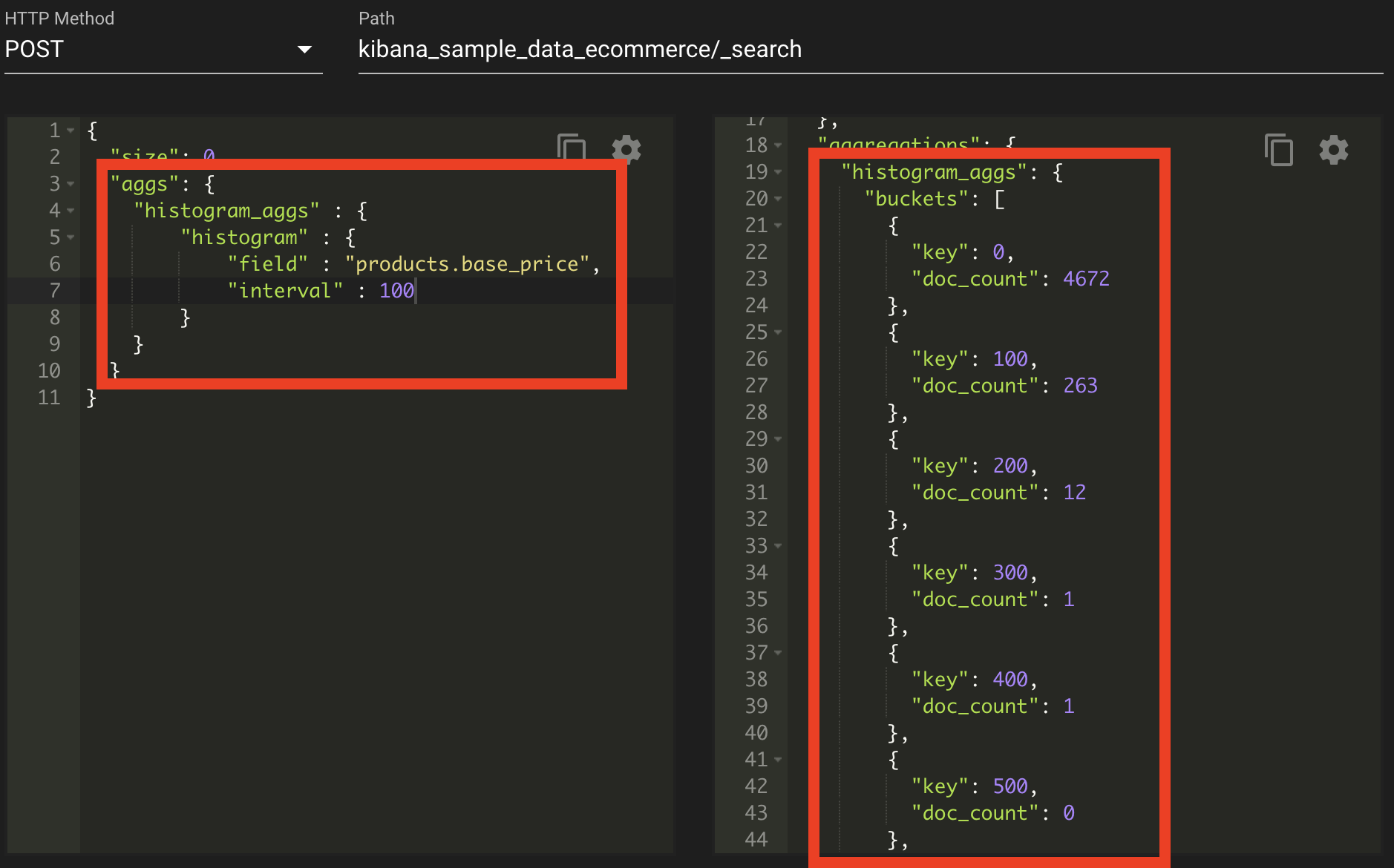
histogram은 숫자 타입 필드를 일정 간격 기준으로 구분하여 집계한다. 이러한 일정 간격 기준은 interval을 통하여 간격을 주었다. 이렇게 historgram 집계의 요청에 대한 응답은 0, 100,200,300,... 1000까지 이루어졌으며, 각 간격에 products.base_price에 대한 products가 어떻게 분포되어 있는지 알 수가 있다.
histogram 집계는 설정은 간단하지만 각 버킷의 범위를 동일하게 지정할 수 밖에 없다는 단점이 있다. 그리고 특정 구간에 데이터가 몰려있거나 데이터 편차가 큰 경우 모든 데이터를 표현하는데 비효율인 경우가 있다.
범위 집계
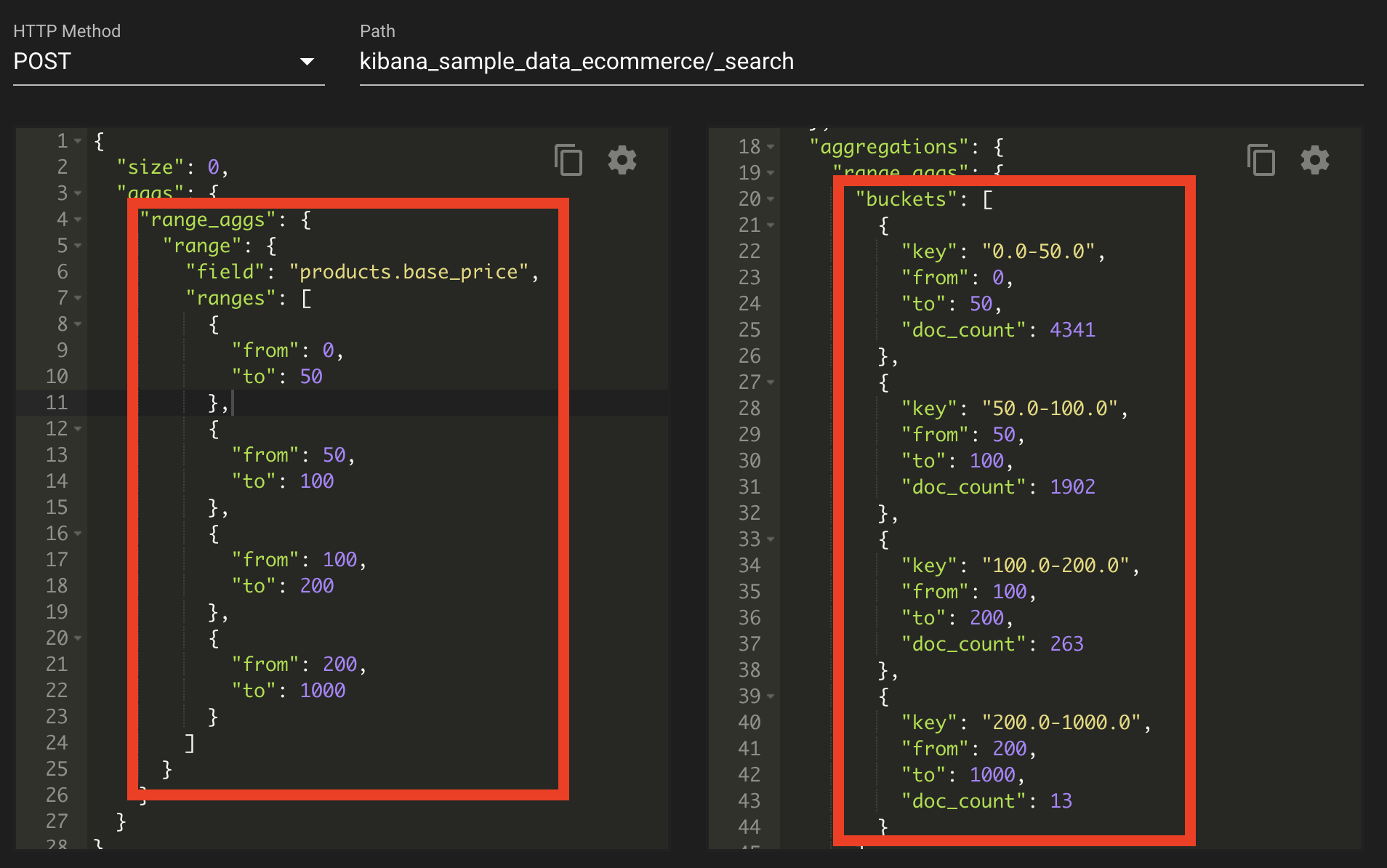
histogram 집계가 특정 구간에 데이터가 몰려 있거나 데이터 편차가 큰 경우 모든 데이터를 표현하는 데 비효율적인 경우가 있다. 이러한 단점을 계선하기 위해서 나온 것 바로 사용자가 직접 버킷의 범위를 설정할 수 있도록 만든 집계가 바로 범위 집계이다.
범위 집계 ? 숫자 타입 필드를 사용자가 지정하는 범위 간격으로 분류한다.
위 범위 집계에 대한 request, response에 대해 일정 범위 내의 세세한 컨트롤이 가능하다.
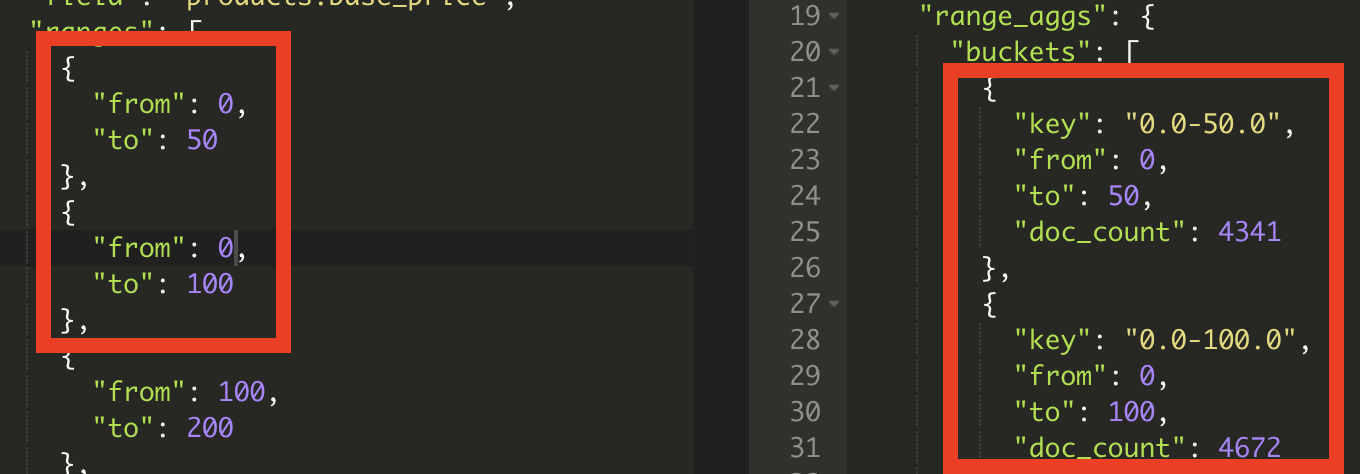
단 범위에 따라 도큐먼트 총합을 구하기 때문에, 겹치는 구간에 대한 합을 구하는 경우 결과 값에 대해 몇몇 데이터가 겹칠 수도 있다.
용어 집계
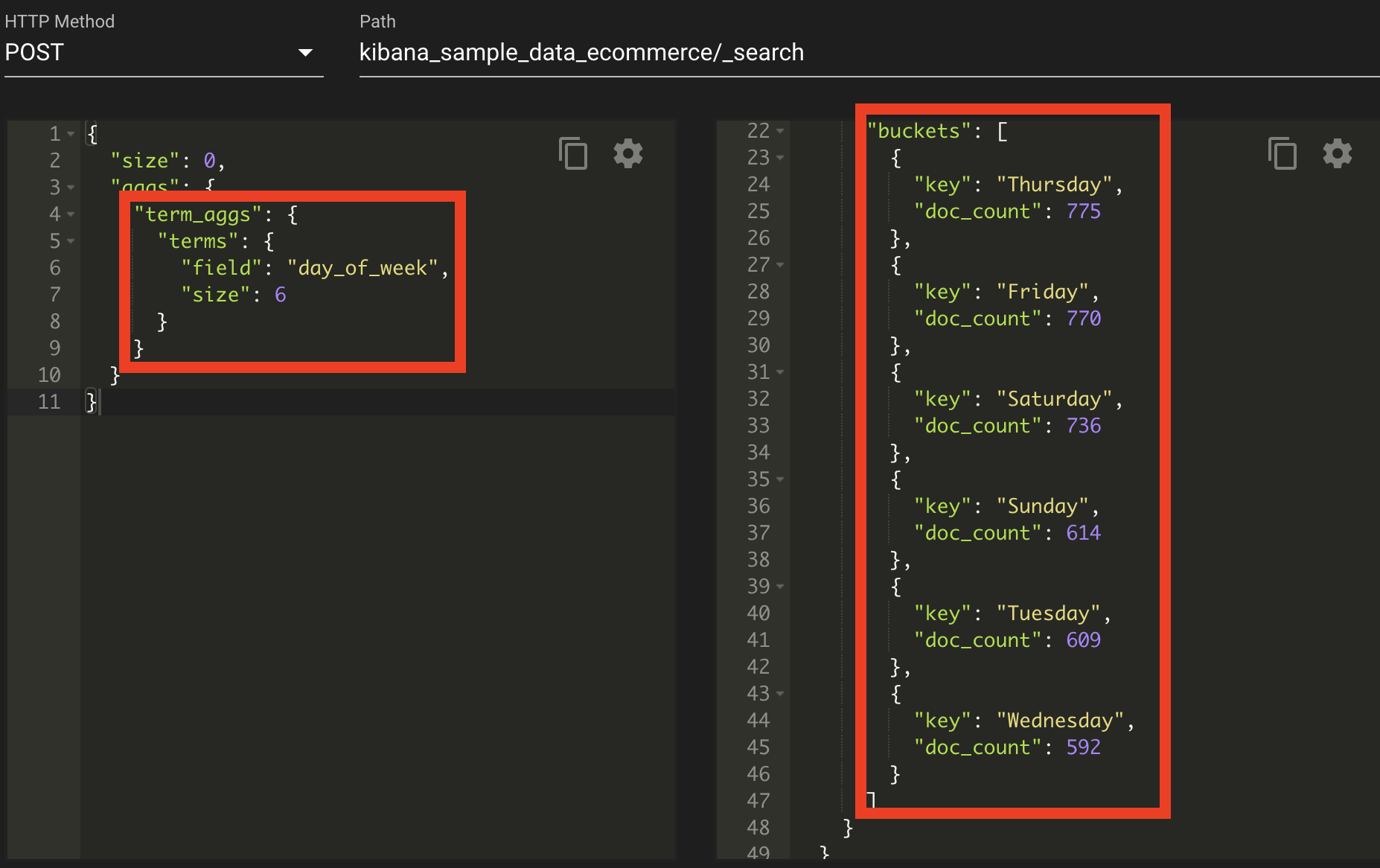
용어 집계는 필드의 유니크한 값을 기준으로 버킷을 나눌 때 사용한다. 위와 같이 day_of_week를 유니크하게 집계했다.
용어 집계 ? 필드에 많이 나타나는 용어(값)들을 기준으로 분류한다.
이렇게 되면 월/화/수/목/금으로 나와야 할 텐데 위의 표를 보면 6개만 나와있다. 바로 size가 6이라는 설정 때문이다. 즉 top 6만 보여준다는 것이다. 다 보여주기 위해서는 size를 없애거나, 유니크 값들의 size를 넣자.
간혹 용어 집계가 정확하지 않는다고 한다. 그 이유는 클러스터일 경우에 대게 발생하는데, 예를 들어 샤드 1과 샤드2가 있다면 샤드1에 대한 탑6와 샤드2에 대한 탑6에 대한 결괏값이 다르기 때문에 이 결괏값을 더하면서 기존과 다른 결괏값이 나올 수가 있기 때문이다. 이러한 경우에는 샤드1과 샤드2에 대해 좀 더 범위를 주면서 결괏값을 더 세밀하게 구해야 한다. 일단 결과 값에 대해서 show_term_doc_count_error : true를 넣고 용어 집계에 대해 다른 결과 값이 나올 수 있는지에 대해 체크한 후 있다면 샤드에 대해서는 좀 더 넓은 범위를 줄 수 있도록 shard_size 를 넣어주면 된다.
집계의 조합
관계형 데이터베이스에서 GROUP BY로 그룹핑한 다음에 통계 함수를 사용하는 것처럼 버킷 집계와 메트릭 집계를 조합하면 다양한 그룹별 통계를 계산할 수 있다.
버킷 집계와 메트릭 집계
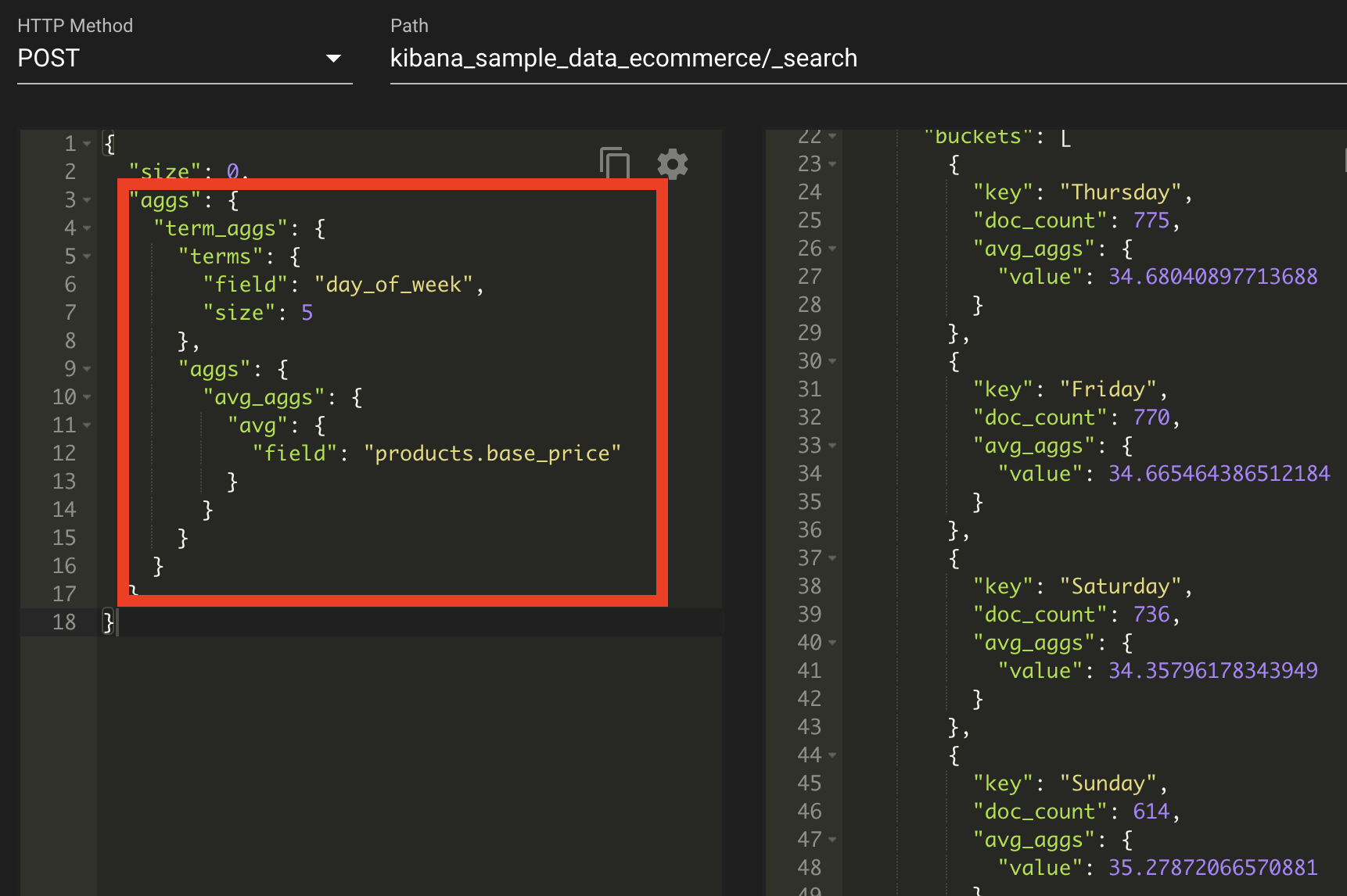
위의 그림은 버킷 집계와 매트릭 집계를 조합했다. 먼저 term_aggs란는 용어 집계를 사용해 요일별로 버킷을 나누고 그리고 그 안에 메트릭 집계인 평균 집계를 용어 집계 내부에서 호출하여 term_aggs에 맞는 products.base_price의 평균값을 구하도록 되어있다.
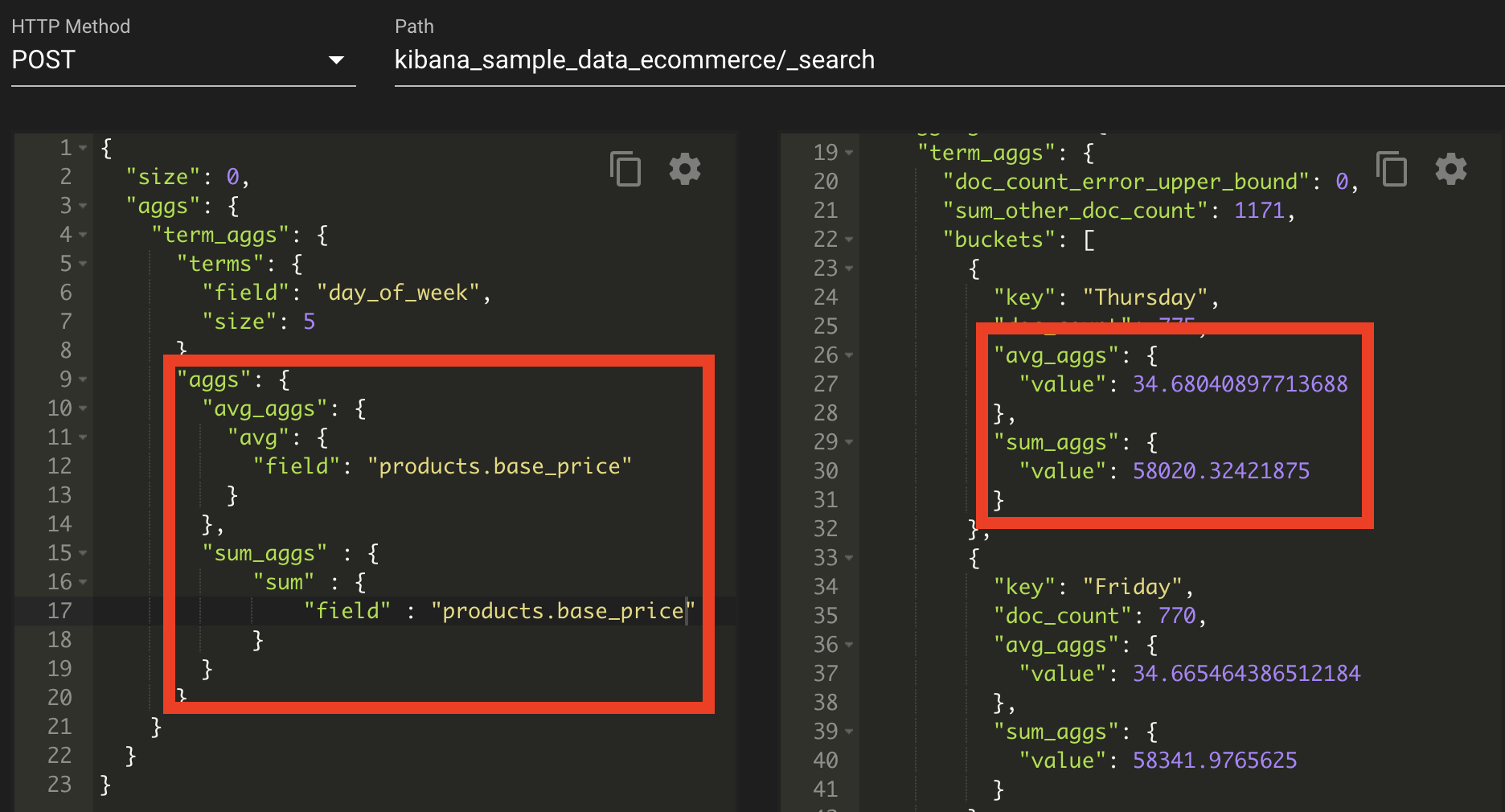
서브 버킷 집계
서브 버킷 ? 버킷 안에서 다시 버킷 집계를 요청하는 집계이다.
버킷 집계로 버킷을 생성한 다음 버킷 내부에서 다시 버킷 집계를 하는데, 트리 구조를 떠올리면 된다.
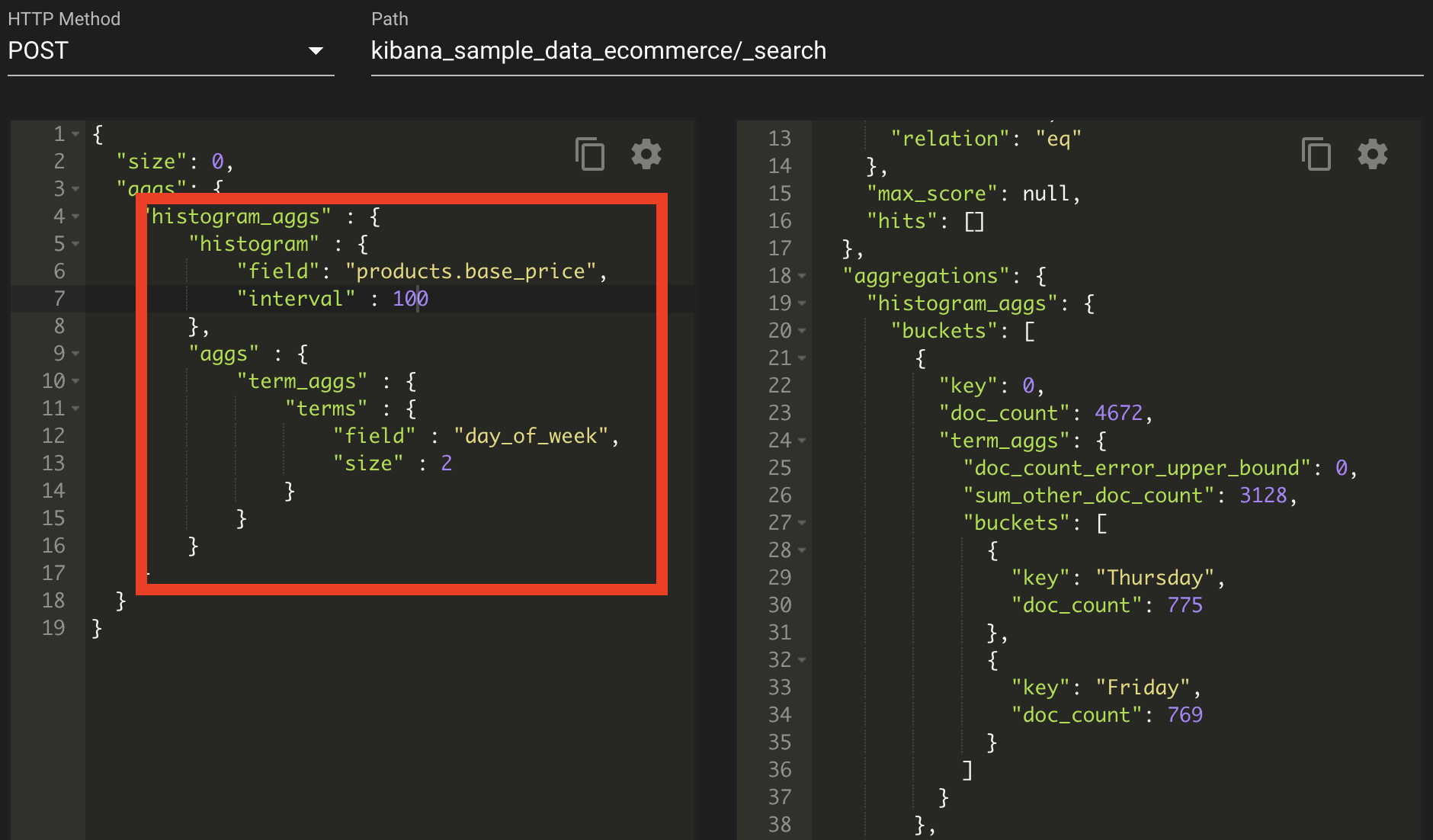
파이프라인 집계
파이프라인 집계 ? 이전 결과를 다음 단계에서 이용하는 파이프라인개념을 차용한다. 엘라스틱서치 파이프라인 집계는 이전 집계로 만들어진 결과를 입력으로 삼아 다시 집계하는 방식이다.
파이프라인 집계 종류
| 형제/부모 집계 | 집계 종류 | 설명 |
| 형제 집계 | min_bucket | 기존 집계 중 최솟값을 구한다. |
| max_bucket | 기존 집계 중 최댓값을 구한다. | |
| avg_bucket | 기존 집계의 평균값을 구한다. | |
| sum_bucket | 기존 집계의 총합구한다.을 구한다. | |
| stat_bucket | 기존 집계의 min, max, sum, count, avg를 구한다. | |
| percentile_bucket | 기존 집계의 백분윗값을 구한다. | |
| moving_avg | 기존 집계의 이동 평균을 구한다. 단, 기존 집계는 순차적인 데이터 구조여야 한다. | |
| 부모 집계 | derivative | 기존 집계의 미분을 구한다. |
| cumulative_sum | 기존 집계의 누적합을 구한다. |
부모 집계
부모 집계 ? 단독으로 사용할 수 없고 반드시 먼저 다른 집계가 있어야 하며 그 집계 결과를 부모 집계가 사용한다. 즉, 부모 집계는 이전 집계 내부에서 실행된다. 그리고 결괏값도 기존 집계 내부에서 나타난다.
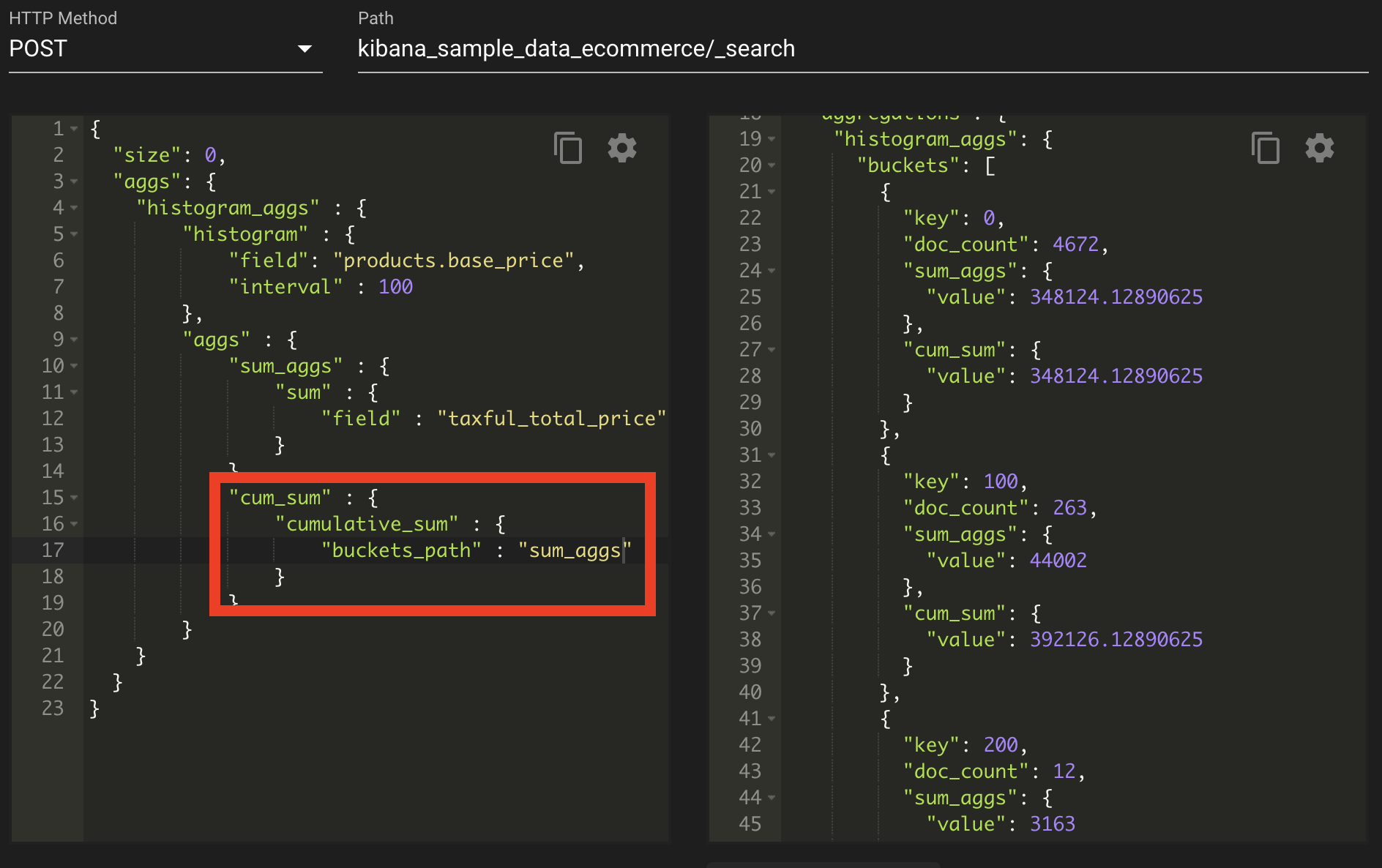
위의 그림은 부모 집계 즉, 누적합을 구하는 부모 집계이다. 이것은 uckets_path : sum_aggs를 잡으면 파이프라인으로 sum_aggs가 집계가 된 후 cum_sum이 진행되는 파이프라인 형태로 흘러간다는 것으로 볼 수 있다.
형제 집계
부모 집계는 기존 집계 내부에서 집계 작업을 한다. 하지만 형제 집계는 기존 집계 내부가 아닌 외부에서 기존 집계를 이용해 집계 작업을 한다.
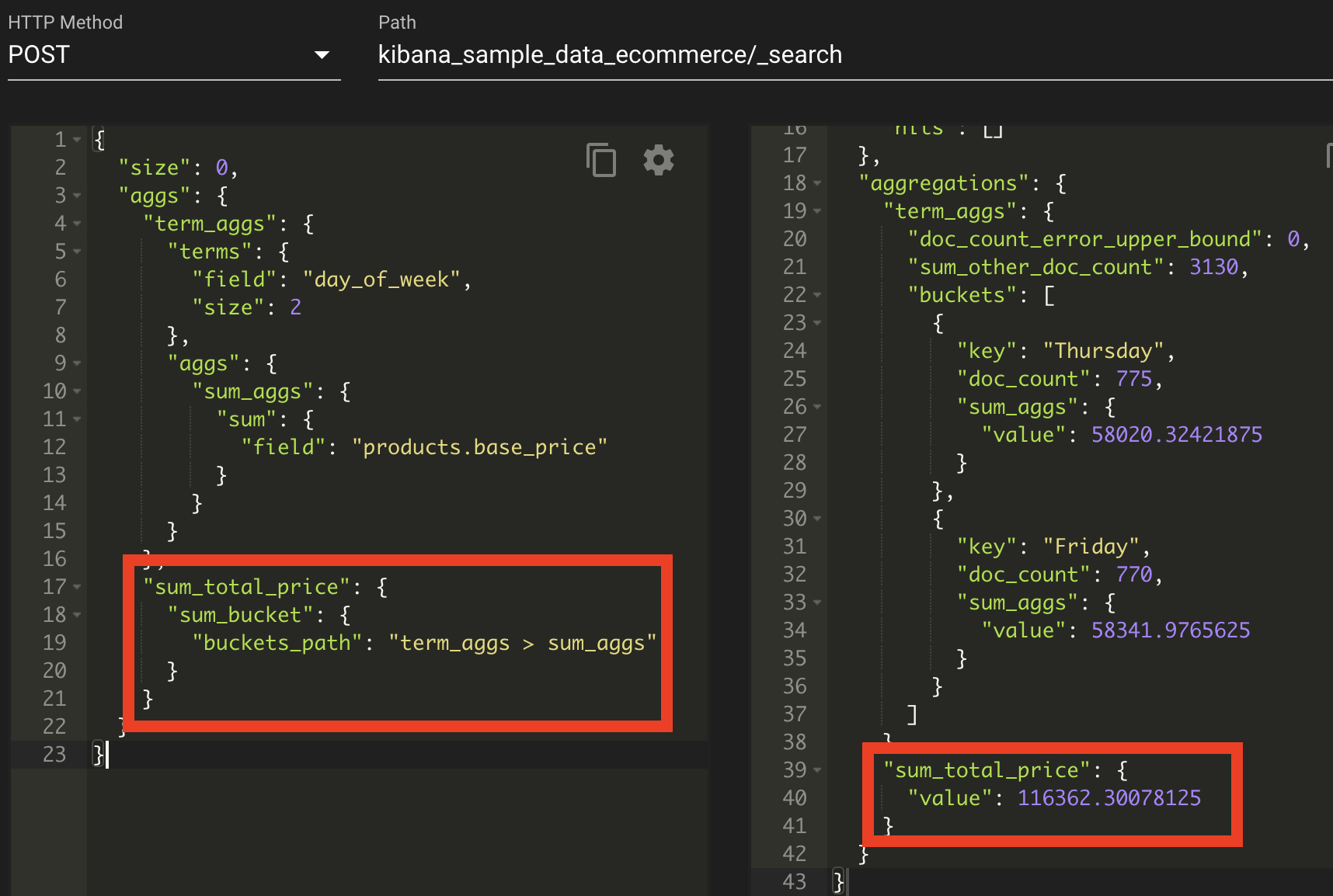
위의 그림과 같이 형제 집계는 밖에서 실행되며, bucket에 대한 패스는 term_aggs > sum_aggs 로 '>' 를 사용함으로써 하위 집계 경로를 지정하여, 집계에 대해 선택한 후 파이프라인 집계를 실행할 수가 있다. 지금은 sum_aggs에 대해서 모두 더하는 파이프 라인 집계가 실행되었다.
회고
요번 챕터는 집계에 대한 기본적인 설명을 해준다. 집계에 대해 처음에는 어리둥절 했지만, 책에 나온 예시를 따라 치는 것만으로도 어떻게 돌아가는지에 대한 흐름을 알 수가 있었다. 그리고 집계에 대한 것 중에 용어집계는 잘만하면 키워드 추천, 인기 검색어에 대한 로직을 만들 수 있을 것 같다. 그리고 키바나가 대표적인 집계 시스템이라고 하는데, 나중에 키바나에 대해 어떻게 집계가 되는지 json request와 response를 까보고 싶어졌다.
우여곡절 엘라스틱서치에 대한 챕터 정리가 끝이났다. 상당히 많은 양인듯하면서, 개인적으로 찾아보았던 자료에 비해 엄청나게 짧은 양이라고 생각이 들었다. 처음에 엘라스틱서치에 대해 일단 진입했을 때 해당 책의 엘라스틱서치 관련 자료를 우선적으로 보면 좋을 것 같다. 왜냐하면 배움에는 단계가 있으니까 말이다. 엘라스틱서치에 대한 기본적인 부분을 보며, 공식문서와 함께 다른 자료를 찾아보고, 좀 더 심화된 책을 보고, 그 외의 경험을 겪게 되는 식으로 말이다.
'ELK > ELK 개발부터 운영까지' 카테고리의 다른 글
| 로그스태시(LogStash) (0) | 2022.03.21 |
|---|---|
| 살려줘!! HyperLogLog (2) | 2022.03.18 |
| 엘라스틱서치(elasticSearch) 검색 - 2부 (0) | 2022.03.02 |
| 엘라스틱서치(elasticSearch) 검색 - 1부 (0) | 2022.03.01 |
| 엘라스틱서치(elasticSearch) 기본 - 2부 (0) | 2022.02.23 |